

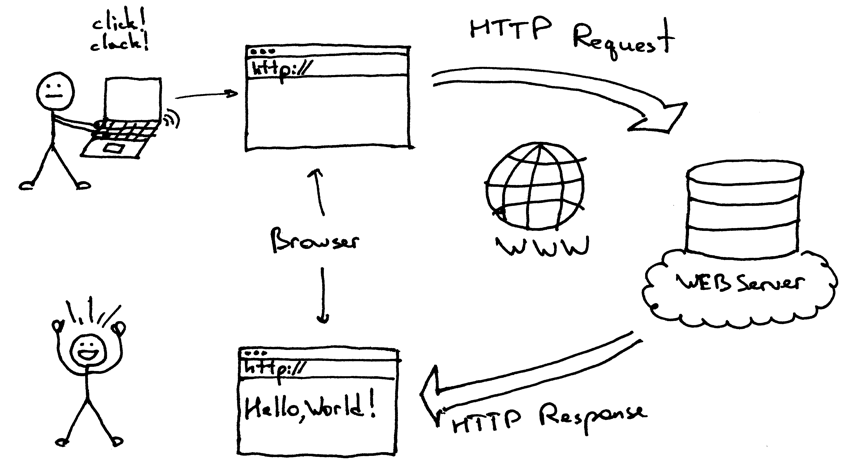
Il y a trop de données à traiter dans l’infrastructure Internet moderne. D’où le concept de sites web qui contiennent une grande quantité de données sur diverses choses dans le monde.
Si les sites web contiennent une grande quantité de données, il est difficile de trouver les données qui sont pertinentes pour un utilisateur particulier. C’est là qu’interviennent les concepts de “web scraping” et de “Scrapingpass.com“.
C’est l’acte d’extraire les données nécessaires et pertinentes de tout site web dont un utilisateur a besoin et nous sommes excellents dans ce domaine. Nous avons tout ce dont un développeur a besoin pour extraire les informations d’un site web.
Notre méthodologie et nos outils sont basés sur une extraction rapide et efficace des informations et supportent plusieurs langues pour la commodité de l’utilisateur.
Nous vous présentons ci-dessous les 7 meilleures bibliothèques de grattage JavaScript pour l’acte de grattage de sites web et vous pouvez également consulter les 10 meilleurs outils de grattage de sites web gratuits.
Vous pouvez également en savoir plus sur le grattage ici.
Monash Data Fluency
Top JavaScript des bibliothèques de grattage de sites web :
1. Requests :
Pour la mise en œuvre d’une utilisation rapide du grattage web HTTP et JavaScript, il s’agit d’une des bibliothèques les plus utilisées et les plus simples qui soient présentes dans JavaScript.
Elle est assez facile à mettre en œuvre et à comprendre et son utilisation est simple. On peut donc l’utiliser facilement sans aucune difficulté pour les complexités.
Elle a également un avantage car elle supporte HTTP5 qui sont dirigés par défaut.

Scrapingbee
Pour extraire le contenu d’une page à l’aide de requests, il suffit de passer une URL, comme le montre l’exemple ci-dessous,
const request = require('request');
request('http://scrapingpass.com', function(er, res, bod) {
console.error('error: ',er) // print error
console.log('body: ',bod); //print request body
});
Ce sont les instructions les plus utilisées et les plus courantes qui existent dans la mise en œuvre de la bibliothèque.
URL ou Uniform Resource Locator :
Il s’agit de l’URL de destination de la requête HTTP faite par l’utilisateur
Méthode :
Une des méthodes HTTP comme GET, DELETE, POST, qui sera utilisée.
En-têtes :
C’est un objet qui sera utilisé, et qui constitue les en-têtes HTTP (clé-valeur)
Formulaire :
La valeur clé des données disponibles est contenue par cet objet.
Quels sont les avantages de l’utilisation des demandes ?
Voici les avantages de l’utilisation de cet objet :
- Authentification de HTTP
- Soutien sous forme de procuration
- Un protocole qui prend en charge TLS/SSL
- Les interfaces de rappel et de streaming sont prises en charge
- La meilleure partie est que la plupart des méthodes HTTP sont supportées comme le GET, le POST, etc.
- Les téléchargements de formulaires sont pris en charge.
- On peut mettre en place l’utilisation d’en-têtes personnalisés.
2. Cheerio :
L’une des célèbres bibliothèques de grattage JavaScript pour le web porte le nom de Cheerio.
- Elle est célèbre car elle donne aux développeurs et aux utilisateurs la liberté de se concentrer sur les données téléchargées plutôt que sur l’analyse des données.
- Un autre grand avantage de Cheerio est qu’il est très flexible et fiable tout en étant rapide, ce qui est une excellente combinaison.
- Il possède le même sous-ensemble du noyau jQuery et, par conséquent, l’utilisateur peut échanger l’environnement jQuery et Cheerio dans la mise en œuvre du grattage web JavaScript, ce qui le rend globalement rapide.
Commencer avec Cheerio est assez simple et voici comment le faire :
var cheer = require('cheerio');
$ = cheeri.load('<h1 id="heading">Hi Folks</h1>');
L’utilisateur peut ainsi utiliser les $ comme il le faisait auparavant dans jQuery
$('#heading').text("Hello Geeks");
console.log($.html()); // return html example : <h1 id="heading">Hello Geeks</h1>
Au final, l’utilisateur devra faire la demande de paquet dans npm install request. Voici comment faire entrer le contenu HTML de www.google.co.in dans votre shell de manière simple et efficace.
var request = require('request');
var cheerio = require('cheerio');
request('http://www.google.com/', function(err, resp, body) {
if (err)
throw err;
$ = cheerio.load(body);
console.log($.html());
});
What are the advantages of using Cheerio?
Parlons des avantages :
- Cheerio étant le sous-ensemble de jQuery, il y a de nombreuses similitudes entre la syntaxe.
- La suppression des consistances DOM permet à l’utilisateur de voir la brillante API.
- Dans le processus d’analyse, de manipulation et de rendu des données d’entrée, Cheerio est assez rapide et aussi, fiable.
- La meilleure chose est que Cheerio est capable d’analyser n’importe quel type de fichier HTML ou XTL, ce qui est tout simplement génial pour les utilisateurs.
3. Osmose :
L’osmose est considérée comme l’une des bibliothèques de grattage de sites web Javascript les plus efficaces et les plus performantes.
- Avec l’osmose, des pages complexes peuvent être grattées sans la connaissance et l’utilisation de beaucoup de codage, ce qui est tout simplement génial pour la plupart des utilisateurs.
- L’osmose gratte et analyse XML et HTML et est implémentée dans node.js, étant emballée avec le sélecteur css3/XPath, et aussi, il y a un emballage HTTP léger.
- De plus, contrairement à Cheerio, l’osmose n’a pas de grandes dépendances, ce qui est très bien.
cron-dev
Pour commencer, nous pouvons voir ci-dessous comment, en utilisant l’osmose, on peut gratter une page Wikipédia qui consiste en une liste des festivals hindous populaires qui sont célébrés à travers l’Inde.
osmosis
.get('https://en.wikipedia.org/wiki/List_of_Hindu_festivals')
.set({ mainHeading: 'h1',
title: 'title'
})
data(list => console.log(list));
Voici le résultat :
{ mainHeading: 'List of Hindu festivals',
title: 'List of Hindu festivals - Wikipedia' }
Parlons du cas où l’utilisateur veut trouver tous les festivals.
Ces données, comme nous l’avons vu, seront disponibles dans le tableau suivant sur la même page. Par conséquent, l’utilisateur mettra en œuvre une autre fonction appelée “trouver”.
Cette fonction sera utile pour la sélection du contexte actuel avec l’utilisation du sélecteur. Ensuite, nous disons à Osmosis de collecter les données de la première ligne, et à la fin, nous obtiendrons les résultats souhaités.
osmosis
.get(url)
.set({ title: 'title' })
.find('.wikitable:nth-child(2) tr:gt(0)')
.set({festival:'td[0]'})
.data(list => console.log(list));
Regardons le résultat :
{ festival: 'Bhogi'}
{ festival: 'Lohri',}
{ festival: 'Vasant Panchami'}
...
Quels sont les avantages de l’osmose ?
Voici quelques-uns des nombreux avantages de l’osmose :
- Les hybrides de sélection comme le CSS 3.0 et XPath 1.0 sont très bien supportés.
- Les pannes de proxy sont faciles à gérer
- Redirige et retouche également les limites.
4. Puppeteer :
L’une des grandes et efficaces bibliothèques de grattage web en javascript qui a été conçue par le célèbre et fiable Google Chrome en 2018 a obtenu de bien meilleures performances que les performances d’autres grandes solutions comme le Phantom JS ou Selenium en comparaison avec la vitesse et l’efficacité.
C’est tout simplement incroyable.
De plus, il est également très stable et peut être facilement utilisé dans le navigateur Chome ou Chromium de Google.
Ainsi, les grandes caractéristiques de celui-ci sont :
- Les différents formulaires de soumission peuvent être automatisés efficacement.
- Des captures d’écran peuvent être facilement réalisées si nécessaire.
- Possibilité de créer des tests d’automatisation
- Création de PDF à partir de pages web sur Internet
Voici comment installer le Marionnettiste dans le projet utilisateur et ensuite, l’exécuter :
npm install puppeteer
Avec cela, un téléchargement de la dernière version de Chromium aura lieu.
On peut également utiliser le noyau Puppeteer si l’on souhaite l’exécuter sur le navigateur Chrome local lui-même.
Quels sont les avantages de l’utilisation de Puppeteer ?
Voyons quelques avantages du Puppeteer :
- Interface de type pointer-cliquer.
- Tracé chronologique si l’utilisateur veut découvrir des défauts.
- Cela permettra à l’utilisateur de faire des captures d’écran.
- Les pages web sur Internet peuvent être créées en fichiers PDF

Medium
5. Playwright
Le playwright est une autre des bonnes et fiables bibliothèques de grattage web JavaScript ouvertes qui ont été développées par la même équipe qui a conçu Puppeteer, mais qui a évolué depuis.
- Elle est conçue de telle sorte qu’elle peut automatiser le chrome de Firefox et aussi, Web Kit avec l’implémentation d’une API unique.
- L’objectif est d’être une alternative au WebDriver qui est un géant dans le domaine de l’automatisation du web du W3C.
Si vous souhaitez l’installer, voici comment :
npm i playwright
L’API est assez similaire à ce qui est observé ci-dessous :
(async () => {
for (const browserType of ['chromium', 'firefox', 'webkit']) {
const browser = await playwright[browserType].launch();
const context = await browser.newContext();
const page = await context.newPage();
await page.goto('http://whatsmyuseragent.org/');
await page.screenshot({ path: `example-${browserType}.png` });
await browser.close();
}
})();
Quels sont les avantages de faire appel à un dramaturge ?
Voici quelques-uns des nombreux avantages :
- Les entrées de la souris et des claviers natifs sont possibles
- Il est facile de télécharger les fichiers de l’utilisateur.
- Il existe des scénarios qui s’étendent sur plusieurs pages et des iframes.
- Émulation des autorisations et des appareils mobiles
Apify blog
6. Axios
Axios can be easily used in the implementation of the front end and also, in the node. js-related back end and stands out of the many javascript web scraping libraries.
- Asynchronous HTTP requests are very easily sent to their REST point at the end.
- Also, CRUD operation performance is very easily done and their implementation becomes very easy because Axios has a very simple package which therefore allows the users to call the web pages from various other locations.
- The Axios library can be used in simple Javascript applications or can be used in collaboration with more complex Vue.js.
Let us take a scenario,
const axios = require('axios');
// Make a request for a client with a given token
axios.get('/client?token=12345')
.then(function (resp) {
// print response
console.log(resp);
})
.catch(function (err) {
// print error
console.log(err);
})
.then(function () {
// next execution
});
Then installing Axios :
npm i axios
This is how bower can be used :
bower install axios
or even yarn :
yarn add axios
What are the advantages of using Axios?
This is quite advantageous to those who know it :
- Requests can be easily aborted
- CSRF protection is already built-in
- Upload progress is supported
- JSON Data Transformation is an automatic process
7. Unirest
Quite a famous library for Javascript web scraping. Ruby, .Net, Python, and also, Java are all supported in this library.
Here is how Unirest is installed :
$ npm i unirest
Simplify requests as given :
var unirest = require('unirest');
What are the advantages of Unirest?
So, these are the advantages :
- Most of the HTTPS method like DELETE, etc are supported
- Forms uploads are supported in case users need them
- Autentication of HTTP is also present
What Does The Verdict Say?
These were some of the best scraping tools present. But, the one we use is ScrapingPass which is excellent in each way possible along with great services.
Using requests can be both, easy and friendly, standing out on the list. There are multiple streams of this river and with such great services, it outperforms most of the javascript web scraping libraries on the list.
But, in general, all of these libraries have performed brilliantly and served countless users. In the end, it all depends upon the user’s contemplation and decision which should be made after checking out his goal, and the features required.
So, it’s the user who has to choose the best from all the javascript web scraping libraries.



Vivek
More posts by Vivek