

Le grattage du Web dans un modèle d’apprentissage automatique :
L’analyse des données est un long processus qui nécessite un prétraitement des données en tant que partie intégrante de celui-ci. Dans le cas de l’apprentissage machine et d’autres théories et projets statistiques, il est nécessaire de conserver les données précieuses et de jeter les données à la poubelle.
Le fait est que les techniques de collecte de données sont souvent peu fiables et que cela entraîne des données inexactes ou des ensembles de données incohérents ou encore des valeurs hors limites.
Il est nécessaire d’éliminer ces données car cela entravera l’utilisation des données, ce qui peut être fait à l’aide du grattage de la toile, et c’est là que nous entrons en scène.
Chez Scrapingpass.com, nous sommes là pour répondre à toutes vos questions concernant le grattage du web.
Le fait est que le grattage peut être une tâche compliquée mais, avec l’aide de nos “robots de grattage”, il devient facile pour tout utilisateur de gratter n’importe quel type de données.
Le codage utilisé dans notre méthodologie est efficace et mis en œuvre à la perfection. Nous avons développé des robots pour gratter les données d’Amazon.com et il n’est pas facile de créer du code de temps en temps.
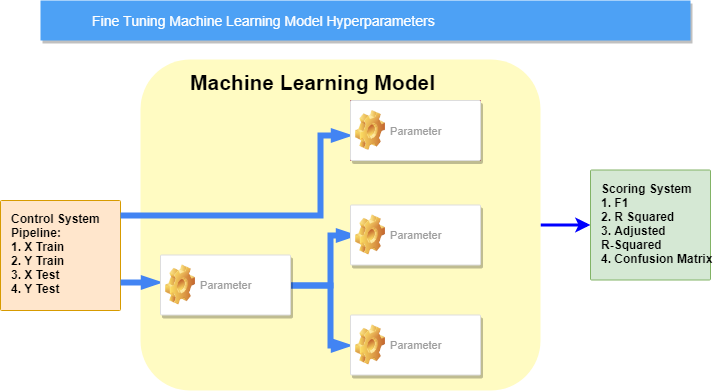
KDnuggets
Comprendre la relation entre le prétraitement des données et le grattage du Web :
- Souvent, l’analyse des données de l’utilisateur nécessite un prétraitement des données. Cela signifie que les données sont analysées de manière approfondie afin de trouver des incohérences.
- Ces incohérences dépendent des méthodes qui sont mises en œuvre et des autres projets statistiques par lesquels les résultats ont été obtenus.
- Le prétraitement des données est assez complexe. Cela ne signifie pas qu’une seule personne doit gérer l’ensemble des données et prétraiter l’ensemble des données par elle-même, mais cela sera beaucoup plus facile si elle le fait elle-même.
- En effet, lorsque plusieurs personnes sont impliquées, il est certain que la charge de travail de chacune d’entre elles diminuera, mais chacune a une approche différente des différentes méthodes statistiques.
- Cela signifie que chaque personne a un état d’esprit différent et qu’il y aura une différence d’opinions et de perspectives pour chacun des ensembles de données qu’elle fournit.
Si nous passons à la définition du prétraitement des données, c’est simple.
On peut dire que le prétraitement des données est le simple acte de suppression des données inutiles ou inutiles de l’ensemble des données. L’ensemble de données peut comprendre divers éléments comme la description des données elles-mêmes ou les informations sur le sujet pour savoir comment les variables statistiques ont été placées ou la description des conditions dans lesquelles elles ont été placées.
Ainsi, il est nécessaire de supprimer toute information qui n’est pas suffisamment digne de figurer dans l’analyse de l’ensemble des données.
Nous examinerons ci-dessous comment le grattage peut être utilisé pour collecter des données à partir des pages web et comment elles peuvent être mises dans un format de fichier CSV et stockées sur la machine locale.
Dans l’apprentissage machine, on peut dire qu’il y a environ 7 des étapes de prétraitement de données les plus importantes dans l’apprentissage machine :
Les sept étapes sont :
- Collecte de l’ensemble des données.
- L’importation de toutes les données et des bibliothèques nécessaires.
- L’ensemble de données est ensuite divisé en deux parties : les variables indépendantes et les variables dépendantes
- Les valeurs manquantes sont traitées.
- Les valeurs catégorielles sont vérifiées.
- Ensuite, le fractionnement de l’ensemble de données a lieu
- Mise à l’échelle des caractéristiques

Hir InfotechMais, ce ne serait pas le meilleur guide s’il n’y a pas d’explication, n’est-ce pas ? Venons-en aux détails.
1. Collecte de l’ensemble des données :
Le grattage de sites web est simplement l’extraction de données de diverses pages web et de sites web sur différents serveurs afin de rassembler toutes les informations ou une sélection d’informations du site web.
Habituellement, les données qui ne sont pas disponibles sur la page principale sont accessibles par un lien qui est affiché sur la page principale est gratté. L’une des méthodes les plus utilisées pour le grattage de sites web est l’utilisation du langage de programmation Python.
- Si le grattage web et les pandas ont tous deux la même approche de la collecte des données, il y a quelques différences minimes qui peuvent être perçues comme des requêtes prenant plus de temps car elles doivent compiler de nombreux fichiers afin d’extraire les données de la page web.
- Cependant, la différence entre les pandas et les demandes est que les premiers permettent de prendre les données requises de différentes manières, tandis que les demandes permettent la même chose, mais par l’utilisation directe de l’URL du site web.
- Le fait est que dans les requêtes, il n’y a pas de restriction quant à la variété des URL, bien que les requêtes soient mieux adaptées aux pages web de grande taille.
- Les demandes sont plus lentes en raison de leur complexité croissante.
C’est l’inconvénient que présentent les deux méthodes, mais c’est quelque chose auquel tout utilisateur doit s’attendre lorsqu’il essaie d’utiliser des langages de programmation modernes et complexes pour parler de manière générale.
Mais, si l’objectif de l’utilisateur est d’extraire des données par le biais d’URL de pages web sur différents serveurs, la différence que ces deux méthodes présentent en termes de vitesse est tout à fait acceptable.
Voici donc quelques outils ainsi que des bibliothèques qui peuvent être utilisés :
- BeautifulSoup est un excellent outil pour extraire des informations via des pages HTML et XML.
- Il permet d’envoyer facilement des requêtes HTTP.
- Des structures de données rapides, expressives et flexibles sont fournies par Pandas.
2. Importation de toutes les données et des bibliothèques nécessaires :
Voici 3 des plus importantes bibliothèques qui seront utilisées dans la méthode de prétraitement des données :
- Pour le calcul de tableaux en langage de programmation Python, le paquet fondamental est Numpy. L’insertion de tout type d’opération mathématique ou l’ajout de tableaux multidimensionnels avec de grandes valeurs ou matrices dans un code peut être fait à l’aide de cette bibliothèque.
- Matplotlib.pyplot peut être utile pour le tracé de différents types de tableaux dans le code et est une bibliothèque Python 2D.
- Pandas est un outil puissant et extrêmement utile qui peut être utilisé pour l’analyse des données ainsi que pour la lecture statistique des données. Il est également très utile dans le cas de l’analyse des séries chronologiques. L’importation et la gestion des ensembles de données sont également très importantes dans ce cas.
3. L’ensemble de données est ensuite divisé en deux parties : les variables indépendantes et les variables dépendantes :
Dans le cas des plateformes et modèles d’apprentissage automatique, il est impératif d’importer l’ensemble de données par l’extraction des variables indépendantes et dépendantes, et donc, il est obligatoire d’effectuer cette étape pour continuer le grattage de la toile.
Lisons le fichier household_data.csv :
import pandas as pd
df = pd.read_csv('household_data.csv')
print(df)
Voici donc ce que l’écran de sortie affichera :
Item_Category Gender Age Salary Purchased 0 Fitness Male 20 30000 Yes 1 Fitness Female 50 70000 No 2 Food Male 35 50000 Yes 3 Kitchen Male 22 40000 No 4 Kitchen Female 30 35000 Yes
Si l’on considère une équation, comme celle ci-dessous :
y=36a + 94b - 2.5c
La valeur de y dépend des valeurs de a, b et c. Par conséquent,
- a,b,c: indépendant
- y: dependent
Voici comment nous pouvons diviser le fichier ci-dessus en formulaires dépendants et indépendants.
x = df.iloc[:, :-1].values print(x)
C’est le résultat qu’obtiendra tout utilisateur donné :
[['Fitness' 'Male' 20 30000] ['Fitness' 'Female' 50 70000] ['Food' 'Male' 35 50000] ['Kitchen' 'Male' 22 40000] ['Kitchen' 'Female' 30 35000]]
Voici comment vous pouvez extraire les variables dépendantes de l’ensemble de données :
y = df.iloc[:, -1].values print(y)
Et voilà !
['Yes', 'No', 'Yes', 'No', 'Yes']
4. Les valeurs manquantes sont traitées :
Les modèles d’apprentissage automatique ont des valeurs manquantes incluses dans l’ensemble de données et il est impératif que l’utilisateur supprime ces valeurs manquantes de toutes les manières possibles, sinon tout le grattage de la bande sera un gaspillage.
Les valeurs manquantes dans l’architecture d’apprentissage automatique sont constituées de zéros.
Cela peut être réalisé par :
- Suppression d’une ligne spécifique :
Considérons une colonne où la valeur du pourcentage de valeurs manquantes est égale ou supérieure à environ 75 %.
Ici, il est donc assez facile de supprimer les valeurs manquantes et cela peut être fait en supprimant simplement la ligne correspondante de cette colonne.
Le fait est qu’il n’est pas nécessaire que le succès de cette méthode soit toujours garanti, mais elle fonctionne dans les cas où l’ensemble de données est constitué d’un chargement de données de déchets.
- Calcul de la moyenne :
Cette méthode est plus performante que la précédente mais fonctionne avec un ensemble de données numériques, et par conséquent, l’ensemble de données peut être constitué de valeurs de salaires, de nombres d’employés, d’âge, ou de toute autre donnée statistique de ce type.
Ici, dans la colonne où les valeurs manquantes sont supérieures à 75 %, la moyenne, la médiane ou le mode est calculé et le résultat est remplacé par les valeurs manquantes.
Cela entraîne l’ajout de la variance des données à l’ensemble de données mais, elle est tout à fait négligeable, et voici comment :
from sklearn.datasets import fetch_california_housing from sklearn.linear_model import LinearRegression from sklearn.model_selection import StratifiedKFold from sklearn.metrics import mean_squared_error from math import sqrt import random import numpy as np random.seed(0) #Fetching the dataset import pandas as pd dataset = fetch_california_housing() train, target = pd.DataFrame(dataset.data), pd.DataFrame(dataset.target) train.columns = ['0','1','2','3','4','5','6','7'] train.insert(loc=len(train.columns), column='target', value=target) #Randomly replace 40% of the first column with NaN values column = train['0'] print(column.size) missing_pct = int(column.size * 0.4) i = [random.choice(range(column.shape[0])) for _ in range(missing_pct)] column[i] = np.NaN print(column.shape[0]) #Impute the values using scikit-learn SimpleImpute Class from sklearn.impute import SimpleImputer imp_mean = SimpleImputer( strategy='mean') #for median imputation replace 'mean' with 'median' imp_mean.fit(train) imputed_train_df = imp_mean.transform(train)
Il fonctionne bien sur des ensembles de données numériques et est donc préférable dans de tels cas. Il existe de nombreuses autres méthodes, mais celle-ci est celle qui peut être utilisée couramment.
5. Les valeurs catégorielles sont vérifiées :
Les valeurs catégorielles sont de deux types : l’une est achetée et l’autre est le pays. Le second en a 3 et le premier a 2 sous-catégories.
Pour traiter les valeurs indépendantes qui sont incorporées dans la matrice “x” dans les étapes ci-dessus, suivons les étapes suivantes :
import pandas as pd
from sklearn.preprocessing import LabelEncoder
df = pd.read_csv('household_data.txt')
X = df.iloc[:, :-1].values
y = df.iloc[:, -1].values
labelencoder_X = LabelEncoder()
X[:,0] = labelencoder_X.fit_transform(X[:,0])
X[:,1] = labelencoder_X.fit_transform(X[:,1])
print(X)
Voici à quoi ressemble le résultat :
[[0 1 20 30000] [0 0 50 70000] [1 1 35 50000] [2 1 22 40000] [2 0 30 35000]]
Ensuite, il y a l’encodage des variables dépendantes dans la matrice “y”. Cela se fait en utilisant le codage de la table comme suit :
labelencoder_y = LabelEncoder()
labelencoder_y = LabelEncoder() y = labelencoder_y.fit_transform(y) print(y)
Voici maintenant à quoi ressemble le résultat correct :
[1 0 1 0 1]
6. Par la suite, le fractionnement de l’ensemble des données a lieu :
- Tout d’abord, il doit y avoir une division de l’ensemble des données en deux moitiés, les parties d’entrée et les parties de sortie.
X, y = data[:, :-1], data[:, -1] print(X.shape, y.shape)
- Par la suite, l’ensemble de données peut être modifié de manière à ce qu’environ 67% puissent être utilisés pour la formation du modèle et le reste pour les tests.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
- Voici comment mettre en œuvre l’ensemble de données dans la procédure de formation :
model = RandomForestClassifier(random_state=1) model.fit(X_train, y_train)
- Par la suite, l’utilisateur doit adapter le modèle afin de faire des prévisions et de les évaluer :
yhat=model.predict(X_test)
acc=accuracy_score(y_test,yhat)
print('Accuracy: %.3f'%acc)
Par la suite, l’utilisateur doit adapter le modèle afin de faire des prévisions et de les évaluer :
(208, 60) (208,) (139, 60) (69, 60) (139,) (69,) Accuracy: 0.783
7. Mise à l’échelle des caractéristiques :
La normalisation est une technique de mise à l’échelle dans laquelle les valeurs subissent un décalage et une nouvelle mise à l’échelle et finissent donc par avoir des valeurs comprises entre 0 et 1. C’est ce que nous appelons la mise à l’échelle Min-Max.

Voici comment fonctionne la formule du processus où xmax et xmin sont des valeurs minimales et maximales et voici le code :
# data normalization with sklearn from sklearn.preprocessing import MinMaxScaler # fit scaler on training data norm = MinMaxScaler().fit(X_train) # transform training data X_train_norm = norm.transform(X_train) # transform testing dataabs X_test_norm = norm.transform(X_test)
Voici à quoi ressemblerait le résultat :
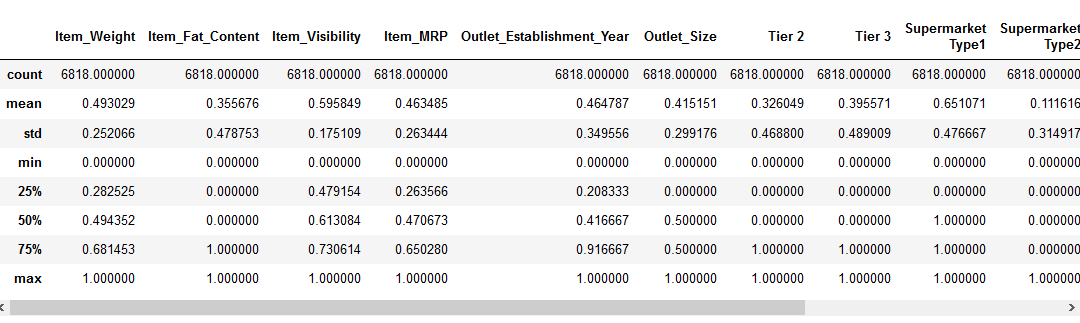
On peut remarquer que chaque valeur se situe entre 0 et 1. Ensuite vient la normalisation.
La normalisation est centrée sur une moyenne qui a un écart-type. C’est ainsi que la moyenne de tous les attributs devient nulle et que la résultante de l’ensemble de la distribution est maintenant égale à zéro.
Voici la formule pour cela :
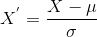
Regardons le code :
# data standardization with sklearn
from sklearn.preprocessing import StandardScaler
# copy of datasets
X_train_stand = X_train.copy()
X_test_stand = X_test.copy()
# numerical features
num_cols = ['Item_Weight','Item_Visibility','Item_MRP','Outlet_Establishment_Year']
# apply standardization on numerical features
for i in num_cols:
# fit on training data column
scale = StandardScaler().fit(X_train_stand[[i]])
# transform the training data column
X_train_stand[i] = scale.transform(X_train_stand[[i]])
# transform the testing data column
X_test_stand[i] = scale.transform(X_test_stand[[i]])
Le look ressemblerait à ceci :
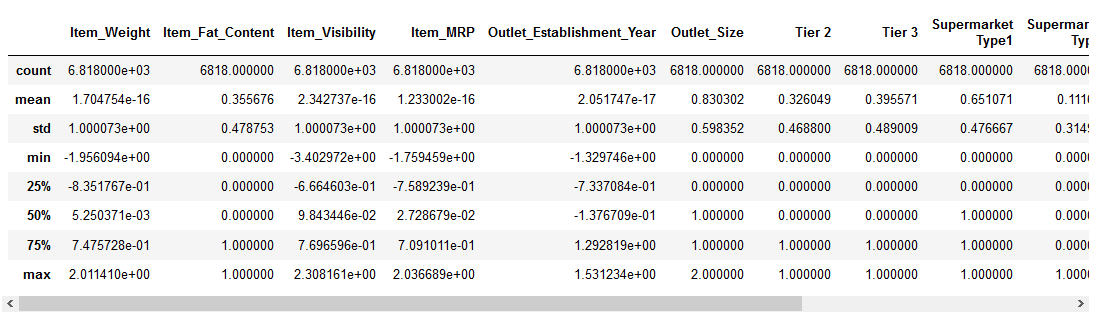
A travers nos yeux :
C’est ainsi que le grattage du web peut être utile dans le processus d’analyse des données par prétraitement des données.
Si un utilisateur a rencontré des difficultés, Scrapingpass.com sera heureux de vous aider pour toute question relative au grattage de sites web.
RocketSource
Dans le guide, nous avons soigneusement présenté la meilleure et la plus efficace des méthodes que vous pouvez utiliser pour mettre en œuvre le concept de grattage de la toile dans le modèle d’apprentissage machine.
Il existe de nombreuses directives qui peuvent orienter toute personne vers la bonne méthodologie, mais celle-ci est la meilleure disponible. Vous trouverez ici tout ce que vous devez savoir sur le grattage de pages web.



Vivek
More posts by Vivek