

Le grattage du Web?
Le processus par lequel un utilisateur collecte des données et d’autres informations pertinentes pour lui à partir de n’importe quel site web peut être qualifié de “grattage du web”.
Il est le plus largement utilisé dans le cas de LinkedIn et d’autres sites web de ce type. Bien qu’il soit illégal d’effectuer du grattage avec l’autorisation du propriétaire du site web, cet article est principalement destiné à des fins éducatives et, par conséquent, aucun grattage illégal n’est encouragé.
Dans certains cas, les gens ne veulent pas voir tout ce qui est contenu dans un site web. Dans ce cas, nos services peuvent être d’une grande aide. En effet, nous avons mis au point la méthode la plus adaptée et la plus efficace pour extraire sans trop de difficultés les données de différents sites web.
Chez fr,Scrapingpass.com, nous avons une équipe d’experts qui ont perfectionné la façon d’extraire des informations, même ‘Amazon.com‘. Ce n’est pas facile à réaliser.
Le codage qui sous-tend cette méthodologie de grattage des données requises de tout site web est un codage régressif et une mise en œuvre efficace. C’est la cohérence à atteindre qui nous a conduit à construire une plate-forme fiable.
Nous pouvons donc dire que nous fournissons l’une des meilleures technologies de grattage de sites web et que nous suivons un algorithme strict. Notre objectif est que chaque utilisateur soit capable d’effectuer le scraping et de connaître la technologie qui se cache derrière.
Pour ce faire, nous disposons de certaines bibliothèques qui peuvent être utilisées efficacement.
Bibliothèques utilisées couramment :
1. Requests :
C’est une de ces bibliothèques qui a la capacité d’extraire les informations données de l’URL qui lui a été fournie.
Le contenu ainsi que ses balises HTML et tous les liens présents dans la page web sont extraits à l’aide de cette bibliothèque avec une grande efficacité.
2. BeautifulSoup :
Le texte brut qui est maintenant extrait avec le BeautifulSoup doit être converti en un arbre HTML afin qu’il puisse être lu facilement par l’utilisateur.
C’est une étape très importante. Elle ne peut pas être manquée. C’est ce qui rend BeautifulSoup très efficace et important cette étape. C’est là que naît le premier pas vers le grattage. La première commande existe ici, dans BeautifulSoup.
L’utilisateur doit implémenter l’installation de la bibliothèque open-source appelée “request”. La commande à utiliser est donnée ci-dessous :
“pip install requests”
Il faut l’entrer dans BeautifulSoup pour faire avancer le processus de grattage de la toile.
Prenons un exemple de grattage de pages web :
C’est ici que nous allons montrer le processus de grattage avec l’aide des bibliothèques mentionnées ci-dessus. Le processus est à nouveau destiné à des fins éducatives, comme mentionné précédemment.
Toute utilisation illicite de la technique ne doit pas être mise en œuvre. En effet, il n’est pas légal de gratter le site web d’un propriétaire sans sa déclaration d’approbation officielle.
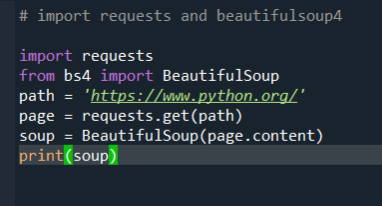
Donc, à des fins éducatives, nous allons supprimer le site avec l’URL : https://www.python.org/. C’est là que sont stockées les informations dont l’utilisateur a besoin.
Nous supprimerons le site pour le nombre de titres présents dans sa structure. C’est là que nous devons procéder à l’extraction du contenu de la page web.
C’est également une étape essentielle et, par conséquent, rien ne doit se passer mal dans chacun des cas. Il existe une méthode à utiliser pour extraire le HTML brut de la page web, qui est présentée ci-dessous :
“requests.get()”
# import requests and beautifulsoup4 import requests from bs4 import BeautifulSoup url = "https://www.python.org/" # using requests to get the content on the webpage page = requests.get(url) # get content of the page into a container named 'soup' soup = BeautifulSoup(page.content,'lxml')
Il ressort clairement des résultats ci-dessus que cette commande qui est donnée en entrée fournira à l’utilisateur un texte clair de l’ensemble du fichier HTML. C’est ce que nous avons cherché à obtenir.
Si vous utilisez cette méthode pour extraire des informations de ‘https://www.python.org/, vous devez vous attendre à ce résultat. Le formulaire peut être différent selon les différentes versions.
Maintenant, l’étape suivante consiste à extraire les informations. La version texte doit être convertie en une arborescence HTML avec les outils de l’avoir. C’est là qu’une autre magie se produit.
BeautifulSoup4 et l’analyseur syntaxique sont utilisés pour mettre en œuvre cette étape et obtenir les résultats appropriés dont nous avons besoin. Mais voici le piège. Le résultat que nous avons reçu n’est pas encore prêt.
Nous devons d’abord examiner et évaluer les résultats reçus. C’est une étape nécessaire avant que l’extraction des données puisse être effectuée à partir de la sortie. En effet, la sortie que nous avons reçue pour l’instant n’est pas dans le format dont nous avons besoin. Le format est de type String.
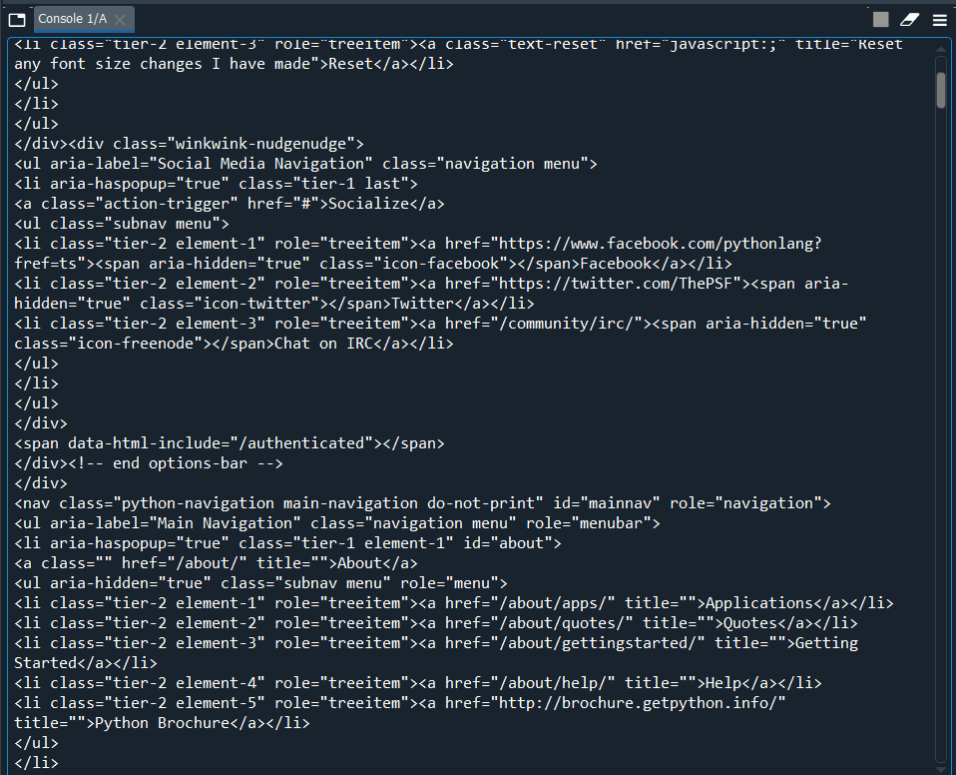
Il s’agit des données textuelles brutes utilisant requests.get() que vous recevrez
Voici la prochaine étape. Le texte en clair n’est pas le résultat dont nous avons besoin et nous devons l’analyser pour le structurer dans un arbre HTML. Mais, si nous devons aller plus loin, nous devrons donner la réponse nécessaire à l’analyseur.
C’est ainsi que nous pouvons voir la sortie nécessaire dans la structure d’indentation appropriée à l’aide d’une fonction qui est énumérée ci-dessous :
“.prettify()”
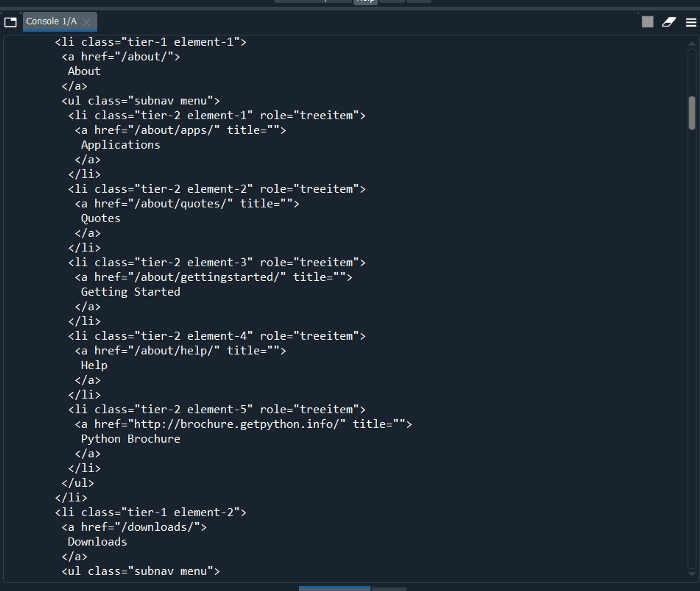
Voici la structure arborescente HTML que nous voulions depuis si longtemps
C’est ici que nous allons maintenant rechercher les informations nécessaires, c’est-à-dire l’étiquette requise.
Nous avons maintenant l’objet HTML analysé, nous pouvons maintenant rechercher l’élément requis. Comme dans notre cas, nous voulons obtenir tous les événements à venir sur la page.
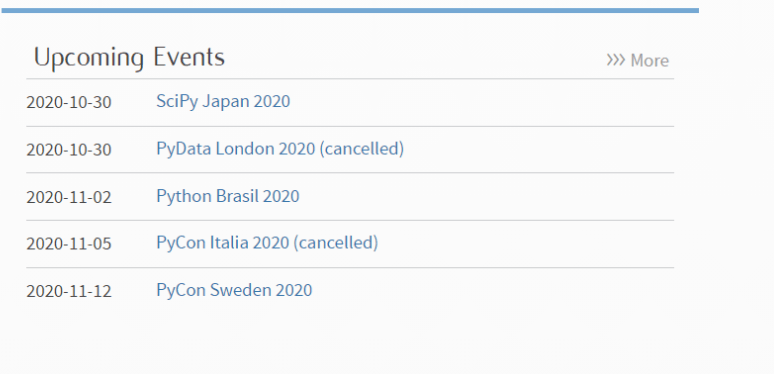
Maintenant, en utilisant la fonction outils de développement et en survolant le contenu pour obtenir la classe et les attributs que nous voulions supprimer. Ensuite, en utilisant le nom de la classe et la commande ci-dessous, nous obtiendrons les éléments que nous voulons.
container = soup.find("div",{"class":"medium-widget
event-widget last"}).find_all('ul')
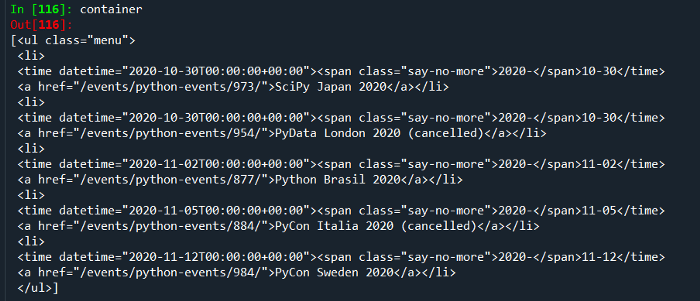
Liste de tous les éléments nécessaires
Comme nous disposons de toutes les valeurs de liste, il nous suffit de sortir le contexte de celui-ci et de le sauvegarder dans une liste. Pour cela, nous utiliserons la compréhension de liste.
La compréhension de liste est un moyen élégant de définir et de créer des listes basées sur des listes existantes. Elle est généralement plus compacte et plus rapide que les fonctions et les boucles normales de création d’une liste.
events = [li.contents[0] for ul in container for li in ul.find_all('a')]
Par la suite, en utilisant la déclaration ci-dessus, nous pouvons enregistrer tous les événements dans une liste appelée “events”. Son résultat est présenté ci-dessous.
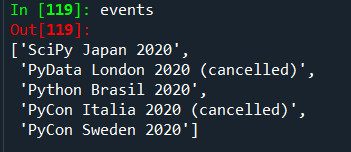
La liste finale des éléments
Et voilà!
Nous vous avons montré comment créer un crawler pour mettre en œuvre le concept de grattage du Web sans aucun effort. C’est assez facile et peut être fait avec l’aide de compétences minimales de codage.
Pour résumer le concept ci-dessus :
Chez fr.Scrapingpass.com, nous avons mis en œuvre avec succès le concept de grattage du web pour l’éducation. Les experts de notre équipe ont conçu des crawlers et des robots araignées qui peuvent facilement vous aider.
L’objectif du scraping doit être d’extraire des informations fiables sous forme de texte ou de CSV. Vous pouvez en savoir plus ici.
Lorsque vous utilisez des robots et des crawlers, vous devez être prudent et les utiliser à la perfection. Tout type d’erreur pourrait nuire à l’ensemble de l’opération.
Bien qu’il ne soit pas très facile de mettre en œuvre cette méthode, il serait certainement facile de l’utiliser avec l’aide de nos robots et robots d’indexation. Avec l’aide de nos services, il vous sera sûrement facile de supprimer n’importe quel site web que vous souhaitez.



Vivek
More posts by Vivek