

Yahoo Finance existe depuis un certain temps et est le holding d’information du géant du web qui porte le nom de Yahoo !
Afin de faire disparaître ce site, nous offrons nos services à toute personne qui cherche à mettre en œuvre l’extraction de données. L’information est une forme de réalisation et nous vous l’offrons.
Mais, il est à noter pour tous et pour tout utilisateur que cet article est destiné uniquement à des fins de connaissance et d’éducation, et par conséquent, nous, à scrapingpass.com, ne promouvons pas ce genre d’activité dans des circonstances illégales.
Qu’est-ce que Yahoo Finance ?
- Il contient une collection de rapports, commentaires, communiqués, nouvelles, cotations, sur le marché financier et l’économie actuelle, ainsi que toutes sortes d’analyses du marché et de cotations d’analystes de premier plan qui existent depuis longtemps et qui connaissent bien le marché.
- En plus de toutes ces informations, Yahoo Finance contient également des outils spéciaux pour ses utilisateurs qui recherchent un soutien et une gestion financière.
- Ce qui rend Yahoo ! Finance très intéressant et remarquable, c’est que chaque information est classée, triée et présentée sous forme de tableau.
- Ces informations peuvent être facilement mises en œuvre sous la forme d’un crawler web qui est utilisé dans le processus de grattage, ce qui peut être très utile pour dire si l’information requise ou l’objectif visé est atteint ou non.
- Bien que cette tâche puisse sembler très facile et qu’il n’y ait pas grand-chose à faire, elle nécessite en fait de grandes étapes ainsi qu’une mise en œuvre correcte du grattage du web.
Des bibliothèques Python pour gratter les données de Yahoo Finance :
Voici quelques-unes des plus célèbres bibliothèques open-source qui seront utilisées par nous dans le cas de l’implémentation de ladite tâche de grattage de données de Yahoo Finance et vous pouvez en savoir plus ici :
- Beautiful Soup est un produit très connu et fiable. C’est donc l’outil parfait pour tout utilisateur qui souhaite extraire des informations de fichiers XML ou HTML et les stocker sur son appareil.
- Request est également très bon et est responsable de la bonne demande des appels HTTP et aussi, de la bonne gestion de la réponse d’une manière efficace et propre.
7 étapes pour supprimer les données financières de Yahoo :
1. L’utilisateur doit s’assurer que les bibliothèques sont déjà installées et qu’aucun délai n’est nécessaire.
En effet, en cas de retard, l’utilisateur pourrait avoir à gérer des erreurs qui peuvent être préjudiciables à l’ensemble du processus de grattage et, par conséquent, le code suivant devrait être mis en œuvre :
pip install requests pip install beautifulsoup4
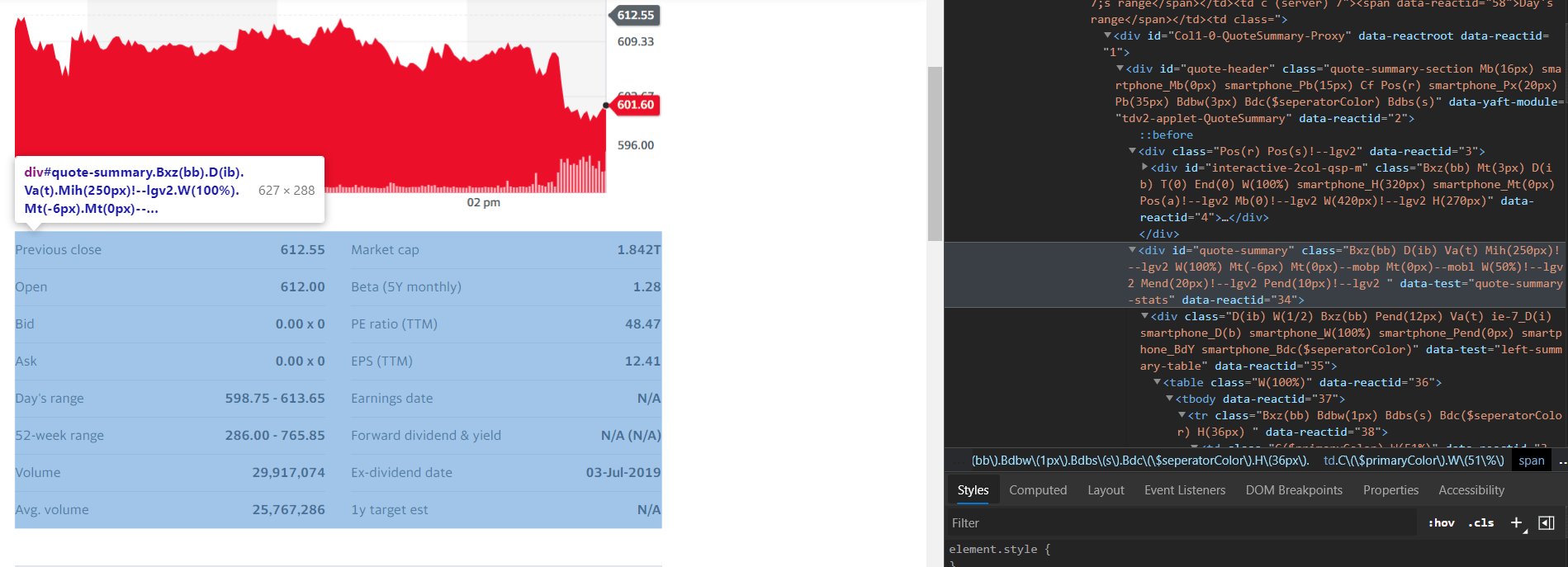
2. Il est nécessaire de bien regarder la page web que l’utilisateur essaie de gratter et de recueillir des informations d’une manière générale.
Afin de comprendre la structure HTML de la page web dans son ensemble, il est nécessaire que la personne qui participe à l’activité inspecte l’élément.
3. La bibliothèque des demandes peut facilement obtenir du site web les données dont l’utilisateur a besoin et le mieux est qu’il n’est pas nécessaire d’utiliser un code très complexe mais plutôt un code très simple de quelques lignes.
C’est ainsi que l’étape de base de tout processus de mise en forme est franchie. L’utilisateur devra importer l’URL requise afin de récupérer un conteneur intitulé “URL”.
import requests from bs4 import BeautifulSoup url = 'https://in.finance.yahoo.com/quote/AXISBANK.NS?p=AXISBANK.NS&.tsrc=fin-srch' page = requests.get(url)
4. L’étape suivante consiste à analyser le texte extrait en données HTML structurées. C’est là que la bibliothèque beautifulsoup entre en jeu, car l’utilisateur l’implémentera dans le processus de grattage.
Cette étape peut également être traitée en quelques lignes de code comme indiqué ci-dessous :
soup = BeautifulSoup(page.text, 'html.parser')
data = soup.find_all('tbody')
5. À ce jour, tout utilisateur aura sauvegardé le “corps” en utilisant la méthode find_all(), également fournie par la bibliothèque beautifulsoup.
Le fait est qu’à partir de maintenant, les données requises sont situées dans deux tables différentes et l’utilisateur devra donc obtenir ces données en utilisant les mêmes lignes du code, mais la variable à utiliser cette fois-ci sera différente, comme indiqué ci-dessous :
# getting tables from the content
try:
table = data[0].find_all('tr')
except:
table = None
try:
table_1 = data[1].find_all('tr')
except:
table_1 = None
6. Dans l’étape suivante, les données seront extraites et sauvegardées à partir des données tabulaires présentes sur le site web, et donc, pour servir à cette fin, de nombreux dictionnaires sont réalisés.
Dans notre exemple de dictionnaire créé, les clés seront le nom qui est fourni aux valeurs sauvegardées, et les valeurs sont celles qui contiennent les valeurs réelles et véritables.
C’est ainsi que cela peut être fait ci-dessous avec un code simple et facile à comprendre :
# declare empty dictionary
final_dict = dict()
for i in range(0,len(table)):
try:
table_name = table[i].find_all('td')
except:
table_name = None
final_dict[table_name[0].text] = table_name[1].text
for i in range(len(table_1)):
try:
table_name = table_1[i].find_all('td')
except:
table_name = None
final_dict[table_name[0].text] = table_name[1].text
7. Et aussi, le résultat sera quelque chose comme ceci :
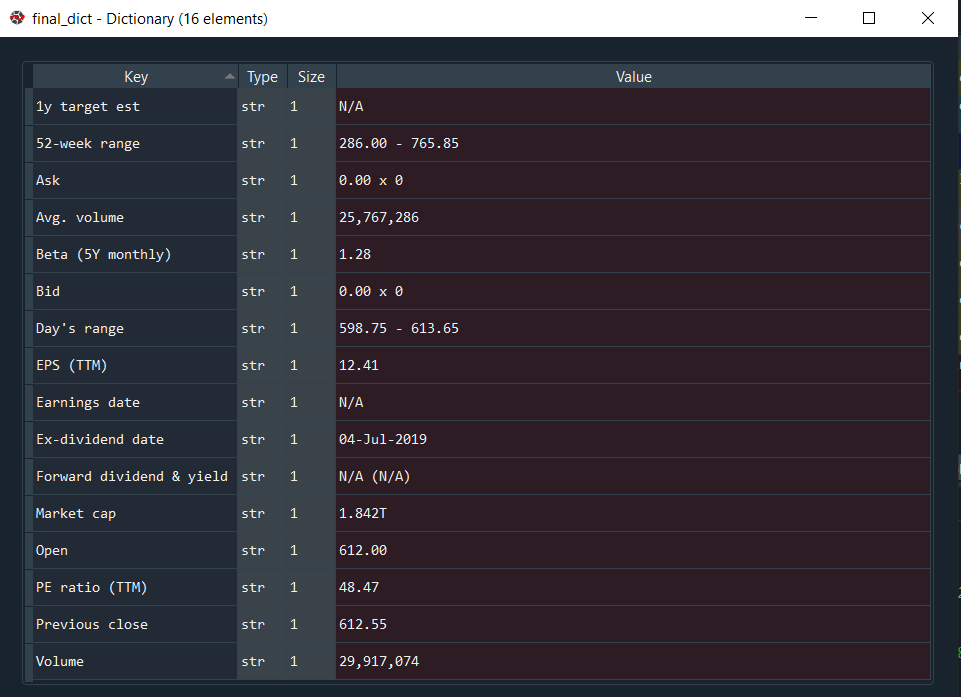
Selon notre compréhension :
Grâce à ce guide, il sera facile pour tout utilisateur d’obtenir n’importe quel processus de récupération d’informations à partir de n’importe quel site web, y compris Yahoo Finance, entièrement automatisé sans trop de perturbations et de tracas et avec un minimum de lignes de codes.
Nous, à Scrapingpass.com, vous avons montré, à des fins éducatives, les moyens de supprimer toute information requise de Yahoo Finance d’une manière simple et facile qui peut être comprise par tout le monde. Vous pouvez consulter d’autres outils ici.
En décrivant l’ensemble du processus d’une manière efficace, nous vous avons montré comment vous pouvez extraire des données de Yahoo Finance en utilisant notre méthodologie et nos outils.



Vivek
More posts by Vivek