

Dans le scénario concurrentiel actuel, les achats se déplacent vers un environnement sans tracas et offrant de nombreuses variantes de produits, à savoir le commerce électronique. Si vous gérez une entreprise de commerce électronique, vous pourriez avoir besoin d’une sorte de gratte-données Amazon avec lequel vous pourriez vous démarquer de la concurrence.
Le commerce électronique étant en plein essor, la concurrence augmente de manière exponentielle, on peut avoir un avantage si l’on peut exploiter la technologie de la bonne manière pour obtenir des informations et analyser le marché afin de mieux adapter le produit au marché. Nous pouvons gratter les informations du site Web de commerce électronique pour obtenir des informations telles que les prix et les avis sur les produits.
Dans ce blog, nous discuterons de la manière dont nous pouvons extraire des liens d’Amazon vers les prix des produits et les avis. Nous vous recommandons de consulter la FAQ sur le grattage de sites web avant de lire cet article. Pour ce faire, nous utiliserons Python et certaines bibliothèques open source pour servir nos objectifs tels que Requests et SelectorLib.
Paquets à installer pour Amazon Data Scraper :
-
Requests :
C’est un paquet python open-source qui est utilisé pour faire des requêtes HTTP et télécharger le contenu de la page qui est la page produit d’amazon dans notre cas.
-
SelectorLib :
Il s’agit d’un paquet python qui est rapidement utilisé pour extraire des données à l’aide du fichier YAML.
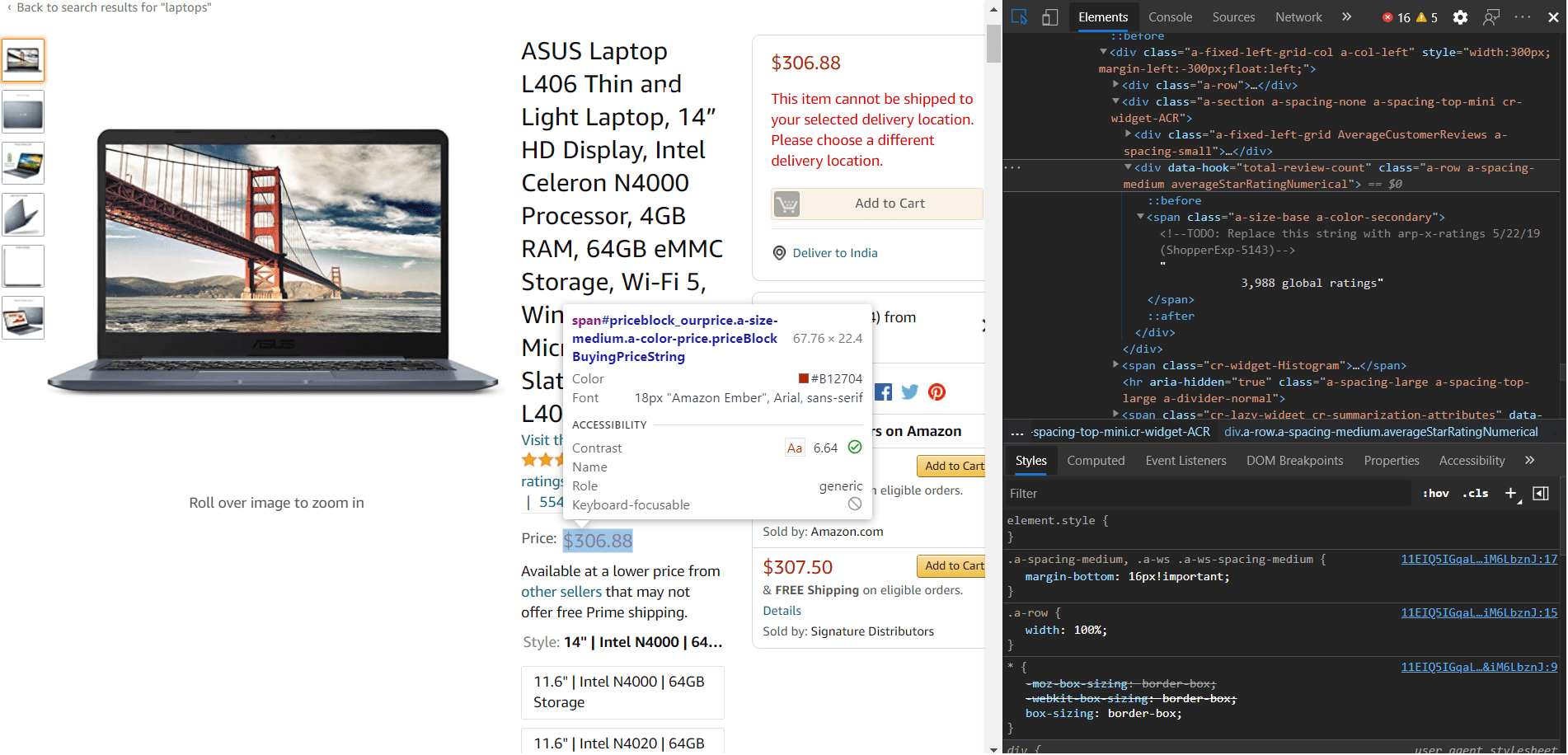
amazon-search-page
Pour cette tâche, nous nous concentrerons sur l’extraction des détails suivants de la page du produit en question.
- Nom
- Prix
- Images de produits
- Description du produit
- Lien vers les revues
4 étapes pour créer un grattoir de données Amazon en utilisant Python
1. Commençons par la structure HTML dans le fichier Selector.yml
Nous devrions d’abord commencer à créer un fichier selector.yml qui contiendra toutes nos balises CSS et le type de structure et les attributs HTML. Pour cela, nous devrons sélectionner des zones à l’aide d’un élément d’inspection ou d’outils de développement utilisant n’importe quel navigateur.
Après avoir soigneusement sélectionné un attribut, vous pouvez enregistrer toutes les informations dans le fichier selector.yml. Pour référence, nous avons ajouté le code des balises ci-dessous.
name:
css: '#productTitle'
type: Text
price:
css: '#price_inside_buybox'
type: Text
images:
css: '.imgTagWrapper img'
type: Attribute
attribute: data-a-dynamic-image
rating:
css: span.a-icon-alt
type: Text
product_description:
css: '#productDescription'
type: Text
link_to_all_reviews:
css: 'div.card-padding a.a-link-emphasis'
type: Link
-
Créer un fichier url.txt pour ajouter des liens vers les articles
Maintenant que nous en avons fini avec les balises, nous pouvons ajouter tous les liens des pages dans un fichier urls.txt. En examinant attentivement, nous avons constaté que la structure HTML est la même pour toutes les pages. Vous pouvez voir le fichier urls.txt ci-dessous.
https://www.amazon.com/ASUS-Display-Processor-Microsoft-L406MA-WH02/dp/B0892WCGZM/ https://www.amazon.com/HP-15-Computer-Touchscreen-Dual-Core/dp/B0863N5FM8/
-
En commençant par le script Python principal pour utiliser ces fichiers :
Maintenant que nous en avons fini avec les exigences de base, nous devons nous concentrer sur le script python qui fera fonctionner ces deux fichiers. Avant cela, assurez-vous que toutes les dépendances sont satisfaites. Nous utiliserons des requêtes pour obtenir des données à partir de la page web. Pour utiliser le fichier selector.yml, nous aurons besoin de la bibliothèque selectorlib et de sa fonction d’extraction qui pourrait être passée comme en-tête dans requests.get().
from selectorlib import Extractor
import requests
import json
# Create an Extractor by reading from the YAML file
e = Extractor.from_yaml_file('selectors.yml')
def scrape(url):
headers = { 'authority': 'www.amazon.com',
'pragma': 'no-cache',
'cache-control': 'no-cache',
'dnt': '1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (X11; CrOS x86_64 8172.45.0) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/51.0.2704.64 Safari/537.36',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,
image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'sec-fetch-site': 'none',
'sec-fetch-mode': 'navigate',
'sec-fetch-dest': 'document',
'accept-language': 'en-GB,en-US;q=0.9,en;q=0.8',
}
# Download the page using requests
print("Downloading %s"%url)
r = requests.get(url, headers=headers)
# Simple check to check if page was blocked (Usually 503)
if r.status_code > 500:
if "To discuss automated access to Amazon data please contact" in r.text:
print("Page %s was blocked by Amazon. Please try using better proxies\n"%url)
else:
print("Page %s must have been blocked by Amazon as the status code was %d"%
(url,r.status_code))
return None
# Pass the HTML of the page and create
return e.extract(r.text)
with open("urls.txt",'r') as urllist, open('output.json','w') as outfile:
for url in urllist.readlines():
data = scrape(url)
print(data)
if data:
print(data)
json.dump(data,outfile)
outfile.write("\n")
4. Génération du fichier output.json en conséquence
Maintenant, nous utilisons des requêtes pour obtenir le contenu HTML et le contenu défini dans le dictionnaire “header” et si nous avons le contenu, nous allons extraire toutes les balises en utilisant la fonction extractor() et retourner le dictionnaire. Après avoir renvoyé le dictionnaire, nous allons l’écrire dans un fichier “output.json”.
Voici donc comment vous pouvez gratter la page de produit Amazon avec ce grattoir de données Amazon pour améliorer votre produit et obtenir des informations, qu’il s’agisse des sentiments des clients ou des prix des concurrents. Il existe d’autres moyens qui peuvent être utiles dans votre cas, mais lorsque nous utilisons le grattage, il y a beaucoup de choses en coulisses que nous devons prendre en compte comme le service proxy, la rotation des agents utilisateurs, la résolution des problèmes de capture, etc. C’est là que le ScrapingPass entre en jeu. C’est là que le ScrapingPass entre en jeu. Nous nous occuperons de tous ces obstacles afin que vous puissiez vous concentrer sur l’amélioration de votre produit tout en tirant parti de nos services.



Vivek
More posts by Vivek